10张图盘点计算机视觉、语音和文本理解里程碑
摘自:新智元
作者:胡祥杰
现在的AI发展到什么水平了?我们总说“超越人类水平”,有没有一个量化的标准,来让我们理性的认识AI发展水平,刺破火热AI的迷雾? 电子前沿基金会 EFF正在致力于这一方向研究。从近期微软宣布语音识别错误率降至5.1%,与人类水平相当谈起,这篇文章将介绍目前AI领域最为知名的发展水平衡量标准,涉及计算机视觉、文本理解、语音识别、翻译、游戏等多个方向。包括ImageNet、 CIFAR-10、 COCO等多个近年来受到广泛关注的数据集以及取得最好成绩的模型的介绍。
微软上周宣布,在语音转文字上,他们的软件取得了新的突破。在一个标准的电话语音通话数据库中,微软的系统的识别错误率为:每20个单词只有1个错误,这与人类的水平相当。
在一系列被人们认为是能证明人工智能的进步正在逐步加速,将大大促进经济增长的证据中,这一结果是最新的一例。
一些软件已经被证明在识别图像中的汽车或猫等对象上能比人做得更好,谷歌的AlphaGo软件已经战胜了多个围棋冠军 ,此前这被认为是需要十年或以上的时间才能实现的。各大公司都急切地希望基于这些进步获得发展,在各家企业的财报电话会议上,AI 被提及的次数更是呈现指数级的增长。
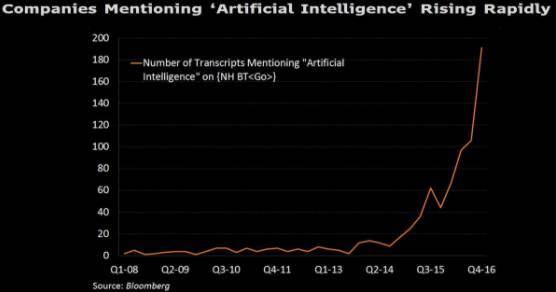
现在,一些AI观察者正在尝试制作更加精确的图,以展示这一技术是如何快速发展的,以及进步的速度如何。通过在不同的领域衡量AI的进步,他们希望能刺破AI泡沫和迷雾。这些项目致力于给予研究者和政策制定者一个更加清晰的视角,让他们能以最快的速度发现领域内哪些地方在快速进步,以及我们应该如何做出反应。
图像识别软件在2016年的标准ImageNet测试中超越了人类。非营利实验室SRI国际研究员Ray Perrault说:“需要这么做的一部分原因,是因为在关于AI 会走向何方这一话题上,人们有许多疯狂的想法”。他是一个名为 “AI指数” 的项目的领导者之一,其目的是在年底前发布一份关于该领域进展情况的详细情况。该项目得到了2015年在斯坦福大学建立的“人工智能百年研究”的支持,以检验人工智能对社会的影响。
关于 AI 取得进步的声明几乎是无处不在的,即使是在快餐和牙刷的营销人员口中。另外,对于那些拥有最坚实的研究团队发布的成果,我们也很难去评估。
去年10月,微软就首先公布在语音识别上达到了人类的标准,但是,IBM和众筹公司 Appen紧接着就公开宣称,人类能做到的准确率要比微软所声称的高得多。接下来,微软不得不其错误率再降低12%,以达到“人类水平”(human parity)。
注:微软最开始宣布语音识别错误率为6.3%,一个月后宣布达到5.9%,最近一次宣布错误率已经降到了5.1%。
AI指数:记录AI发展里程碑的10张趋势图
EFF是一家致力于保护公民自由免受数字威胁的电子前沿基金会,他们已经开始自己的努力来衡量和理解AI的进展。这家非盈利组织正在梳理微软等等机构的论文,以组建一个开源的、在线的数据库,以衡量的AI进度和表现。 EFF的首席计算机科学家Peter Eckersley表示:“我们想知道AI真正发展到什么地步了,哪些是紧急的任务,哪些是长期的目标,而不是只知道那些让人们过度兴奋的投机版本的AI。”
EFF的数据库包含了从2012年起图像识别快速进展的图表,还有一个图,是关于让软件理解儿童读物的测试,这能让我们了解人类和机器在这一任务上的差距。 “ AI指数”项目正在努力绘制AI子领域趋势图,将最受研究员关注的趋势表现出来。
视觉
1. ImageNet
视觉我们将介绍最知名的10个标志性事件,首先就是大名鼎鼎的ImageNet,大家都知道,ImageNet在2017年是最后一届了。
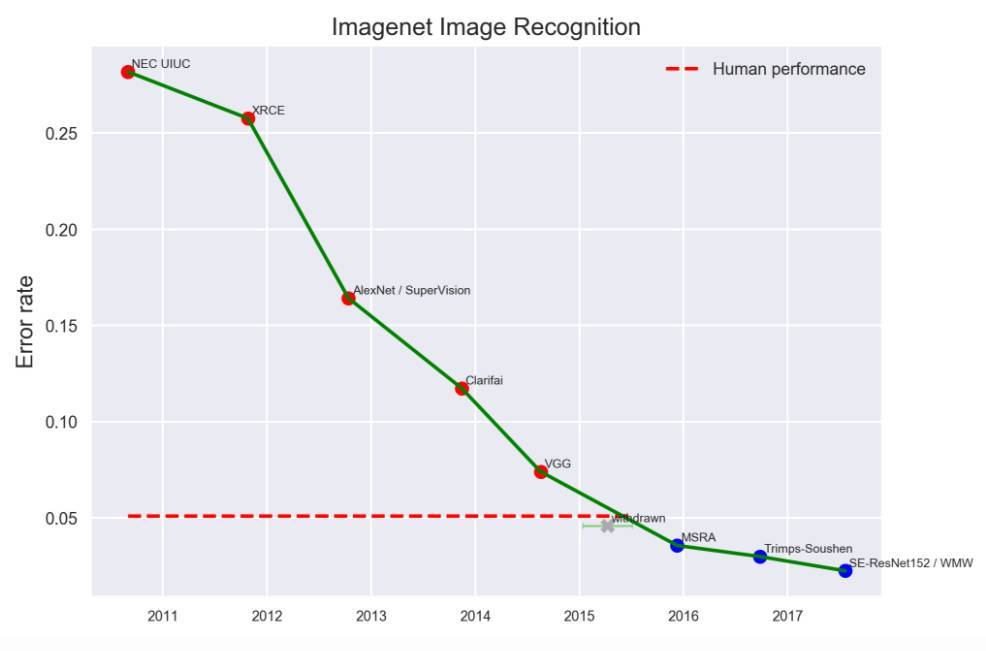
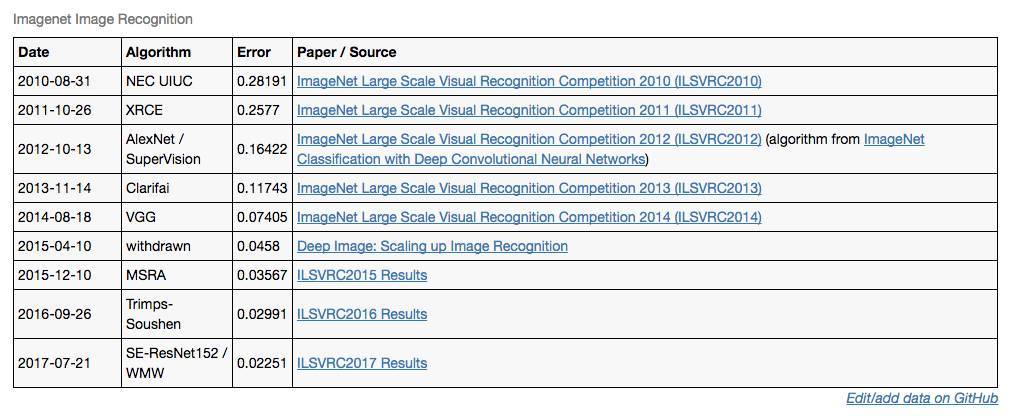
EFF的统计表中列出了从2010年到2017年,ImageNet图像识别竞赛中取得突破的情况。2014年的VGG和2015年的MSRA是两大比较有代表性的突破,其中2015年MSRA的突破,正式将机器对图片的识别错误率降到了人类水平。
2. CIFAR-10 和 CIFAR-100
CIFAR-10 数据库包含了6万张32X32的彩色图像,有10个类型,每个类型有6000张图片。共有5万张训练图像和1万张测试图像。CIFAR-100和 CIFAR-10类似,不同点在于,其类型有100个,每个包含600张图片。
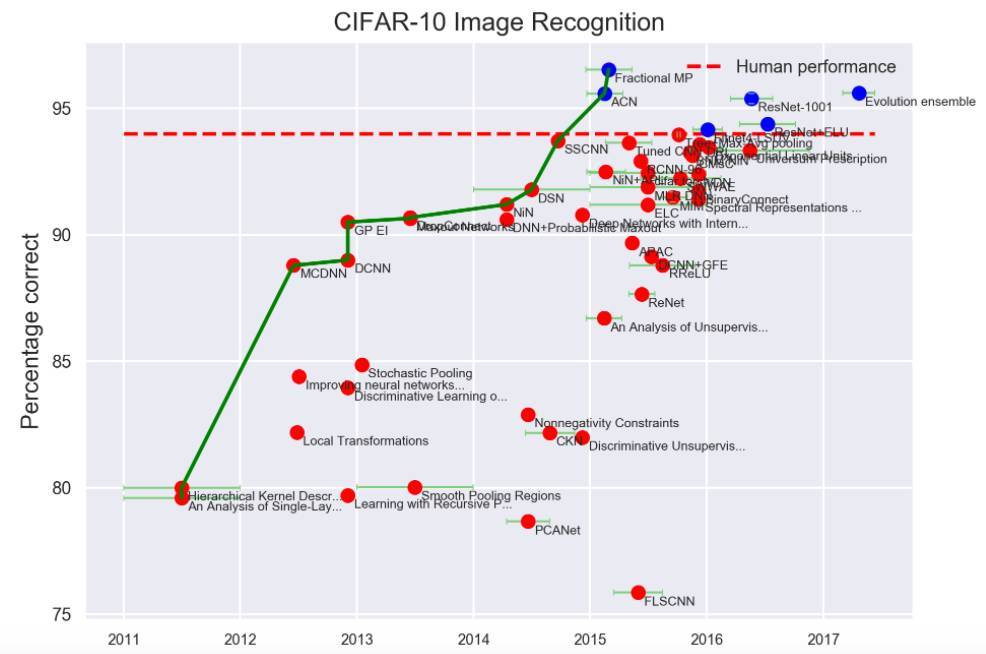
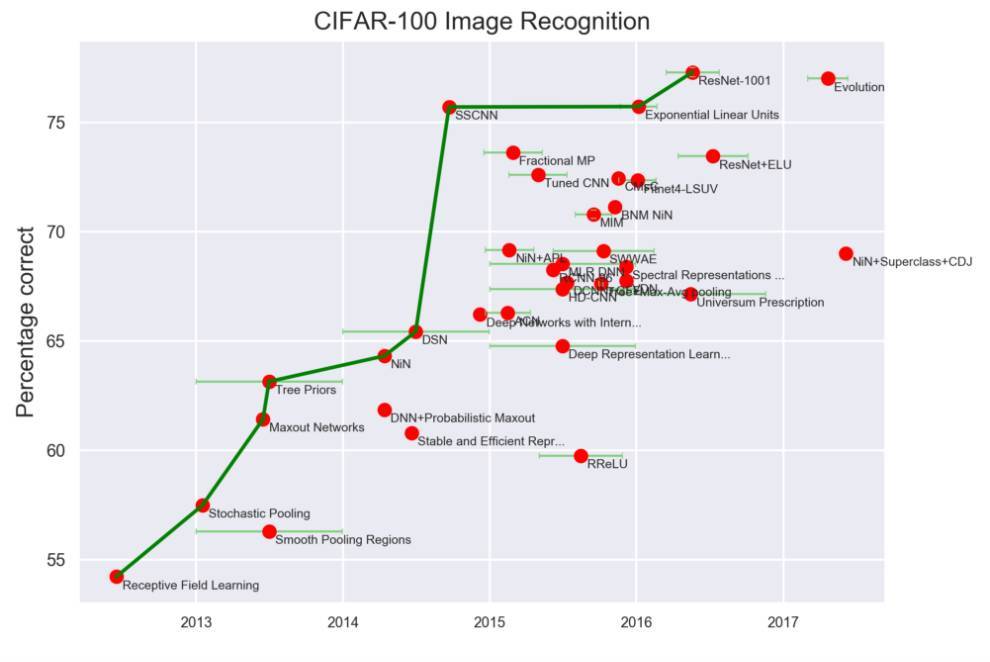
CIFAR-10 中,取得达到人类水平的突破也是发生在2015年之后。下面是具体的算法和准确率:
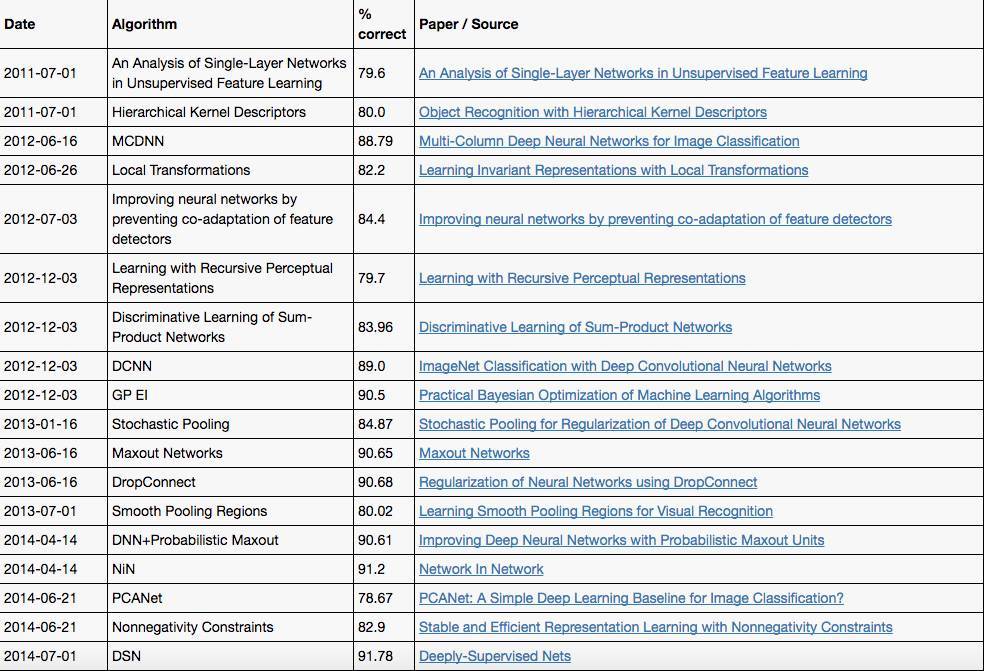
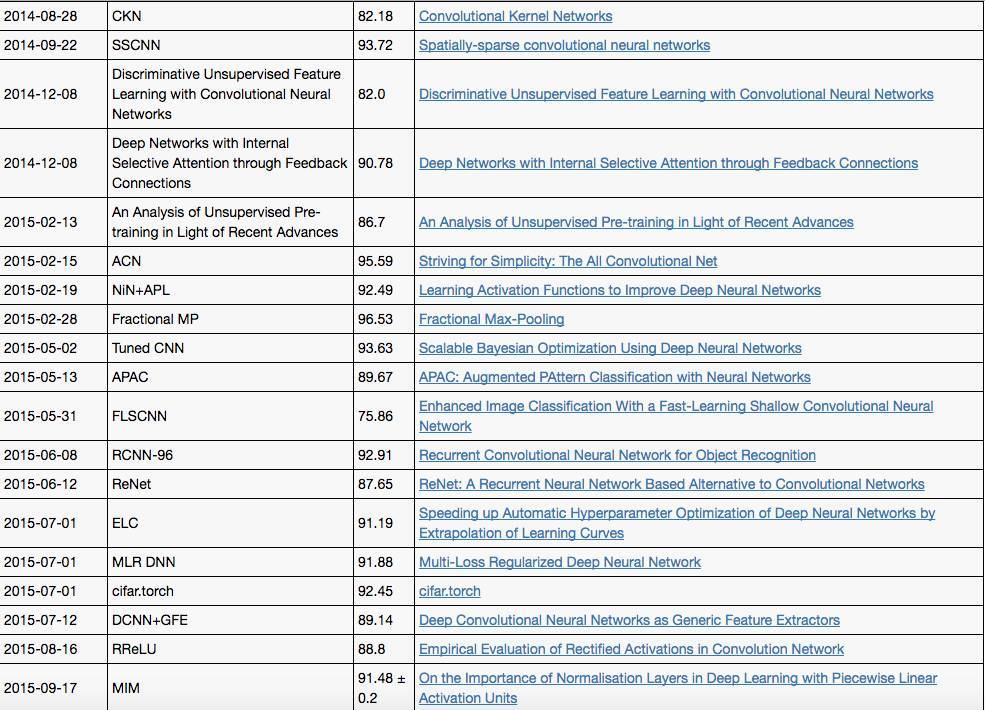
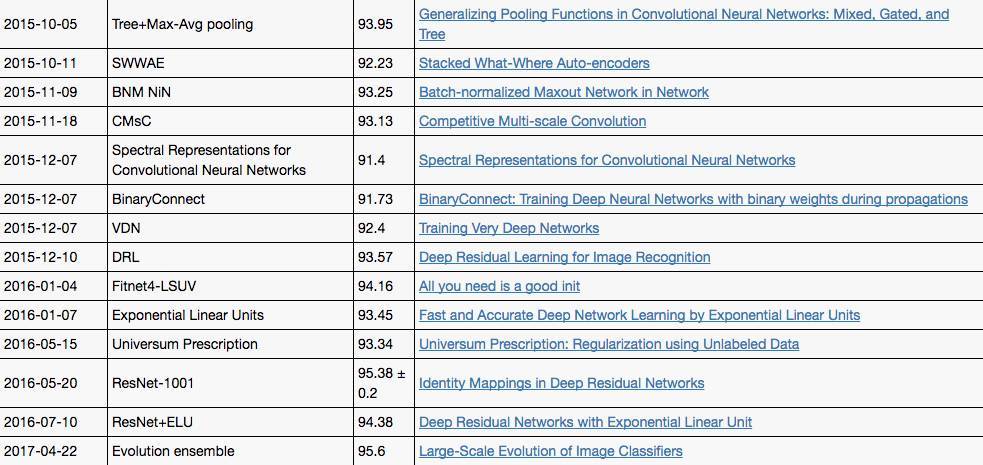
此外,EFF还列出了MNIST 手写识别、MSRC-21、STL-10和SVHN等视觉和图像数据集上几年来的表现,包括算法和论文,详情点击: https://www.eff.org/files/AI-progress-metrics.html#Vision
值得一提的是,视觉问答数据集COCO上的成绩:
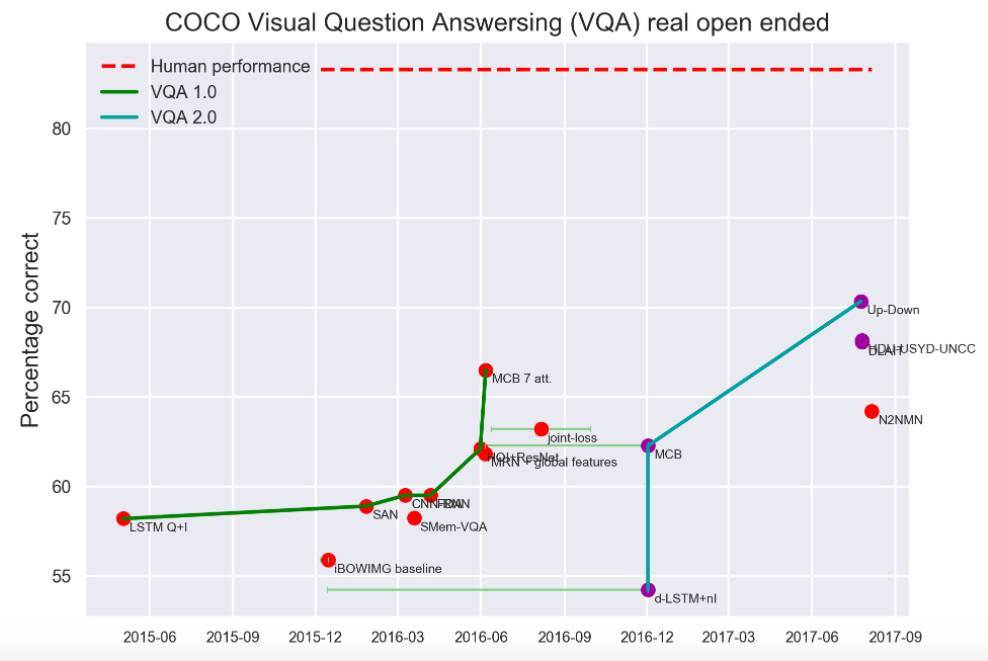
游戏
游戏部分分为:抽象策略游戏和实时视频游戏(各种Atari游戏)。较为有代表性的有:
1. 抽象策略游戏(计算机象棋程序)
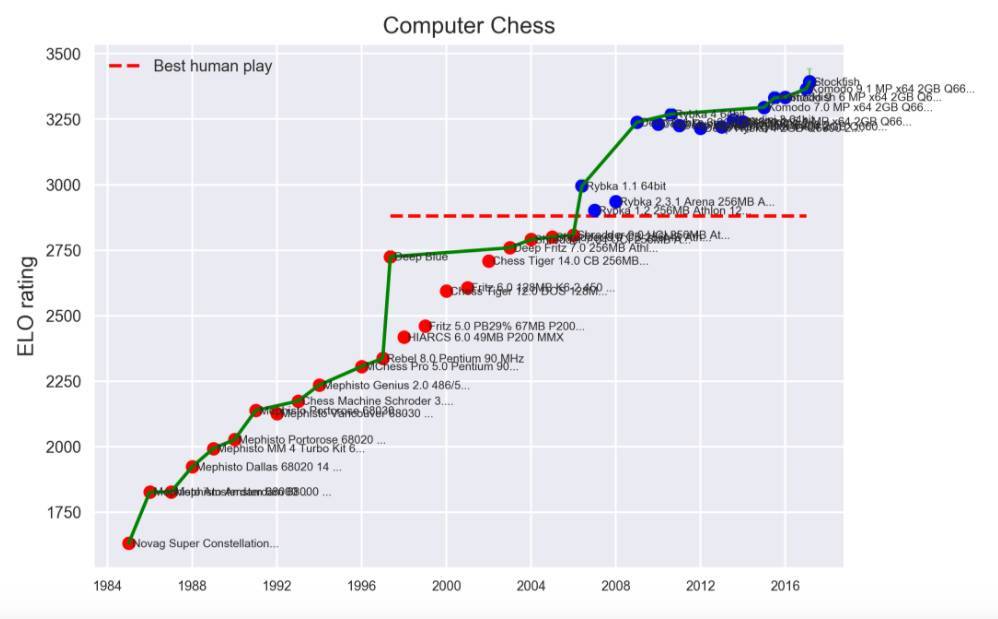
语音识别
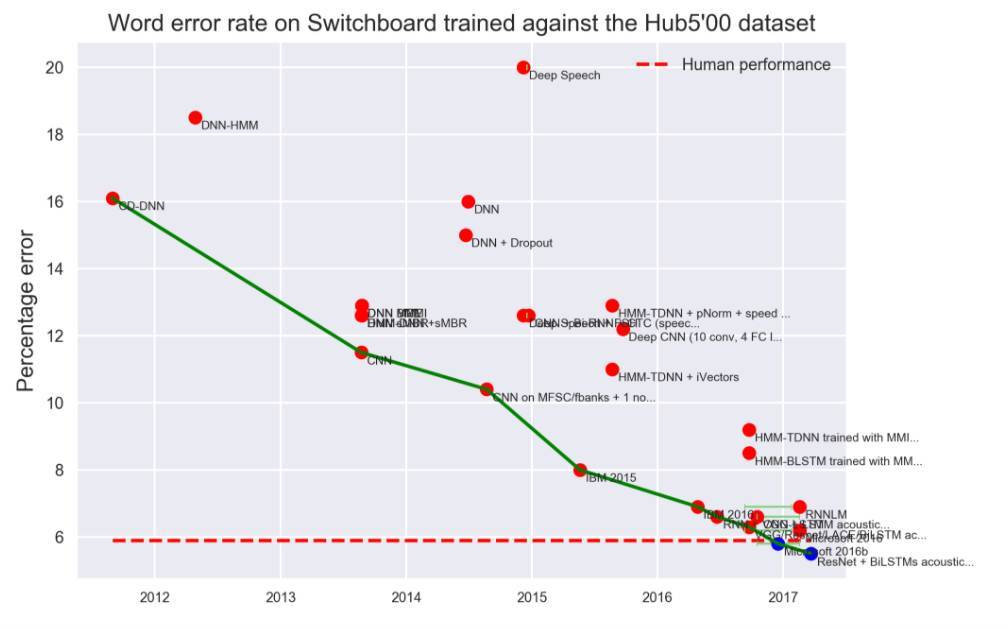
该数据集上近三年来不断刷新新纪录的算法:
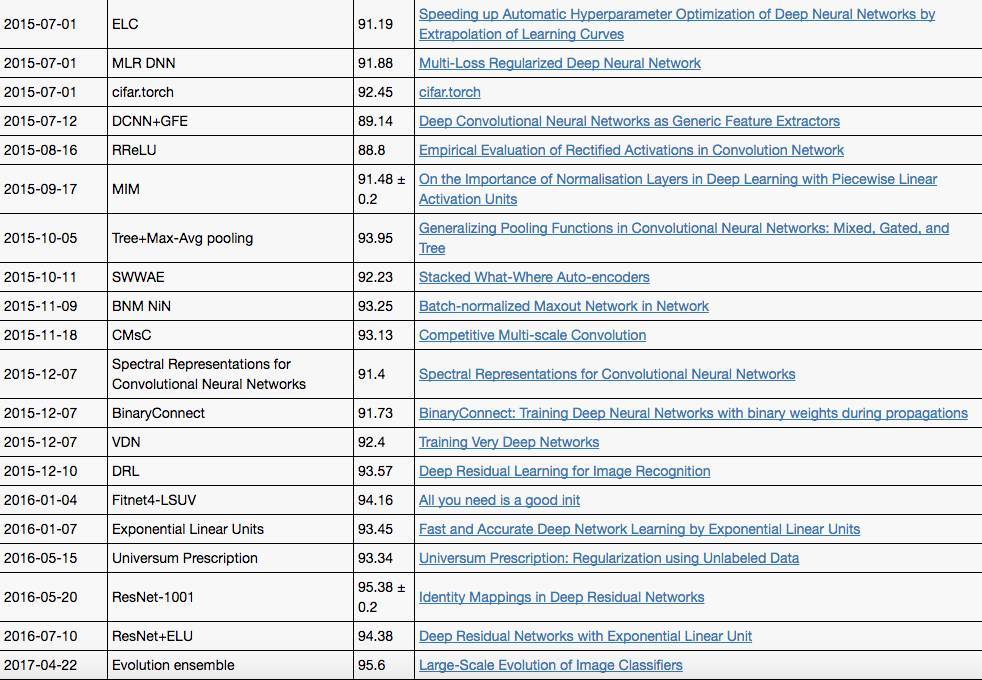
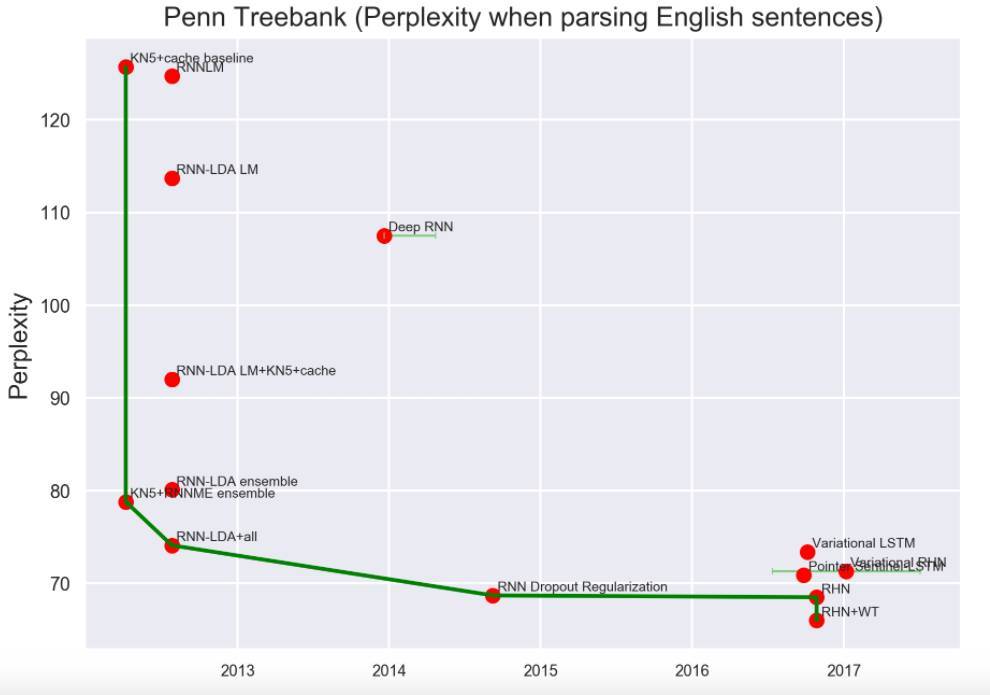
语言建模与理解
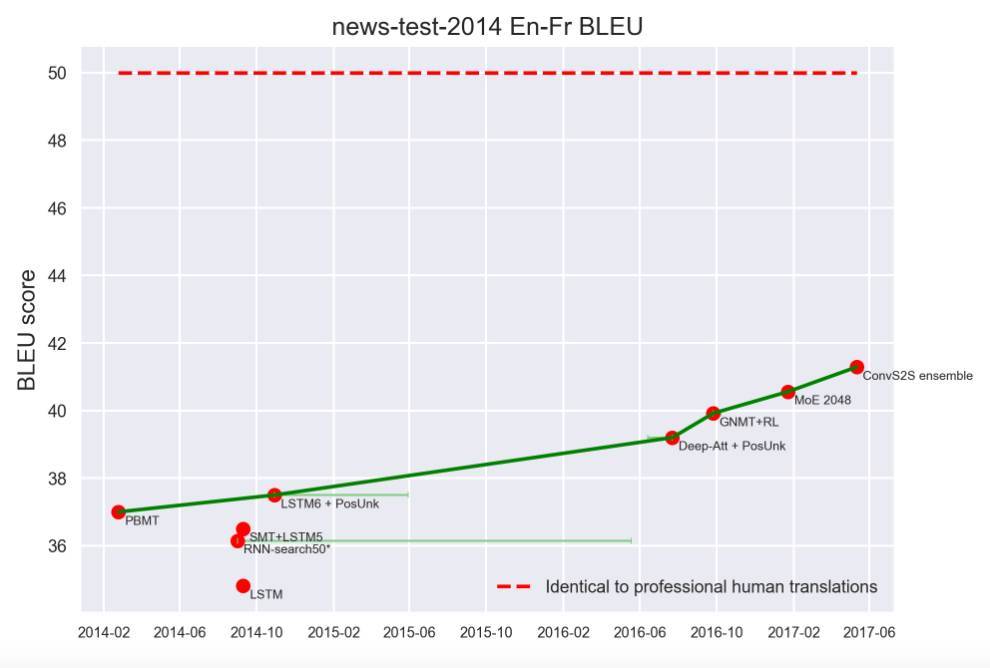
翻译
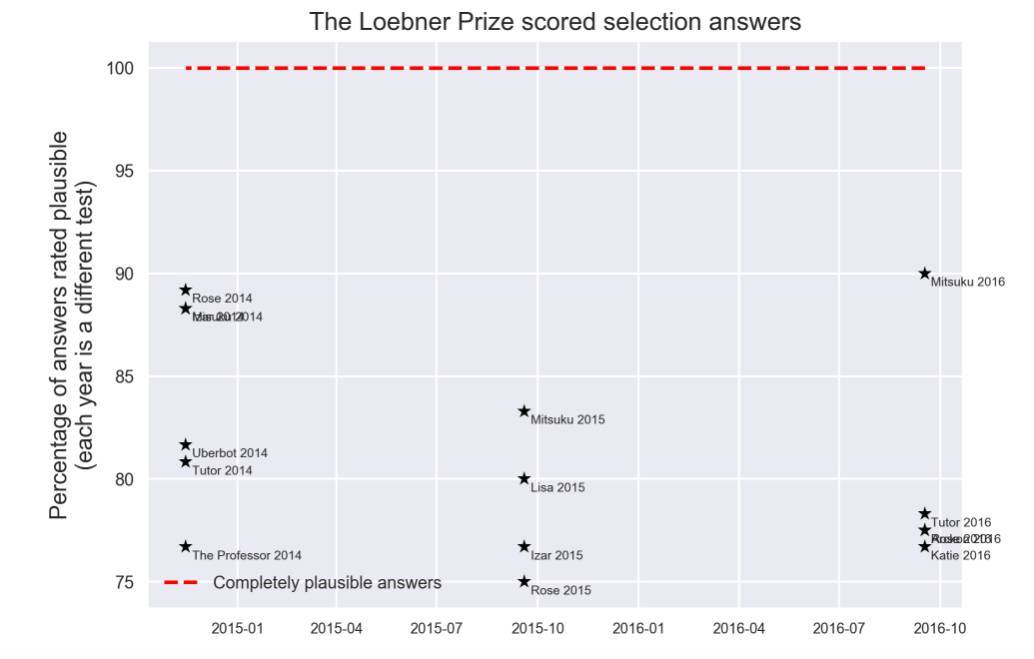
对话:聊天机器人与智能体
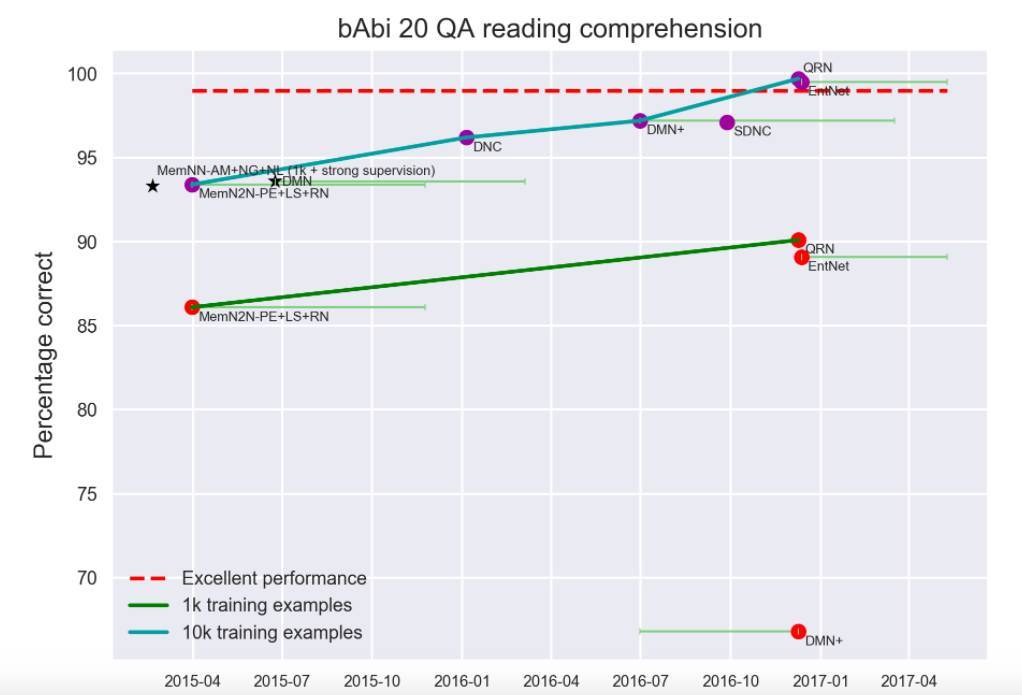
阅读理解
上文提到的视觉、游戏和语音识别等。新智元了解到,EFF目前对AI发展的能力衡量分为以下11个部分:
玩游戏
视觉与图像建模
文本语言
对话语言
音乐信息复合
科学和技术能力
学习:正则化、迁移学习和单次学习
安全
透明性和可解释性
公正与去偏见
隐私问题
更多内容,可点击 https://www.eff.org/files/AI-progress-metrics.html#Vision
趋势图的价值:创造AI版的“摩尔定律”
AI 指数还将尝试监测和衡量人工智能在现实世界中的工作。 Perrault说,例如,将使用该技术的工程师的数量和以AI为中心的公司的投资在图表中进行体现可能是有用的。
他的目标是“了解这项研究对商业化产品有多大影响”,他说。尽管他承认公司可能不愿意发布数据。人工智能指数项目也在跟踪媒体上报道的数量和情绪以及公众对AI的关注。
Perrault说,该项目应该会赢得广泛的观众,因为研究人员和资助机构非常迫切地想看到AI的哪些领域有最大的发展势头,或哪些领域需要支持和新的想法。他表示,银行和咨询公司已经呼吁,需要更好地处理人工智能的真实情况。科技行业与摩尔定律的数十年的“蜜月期”, 证明了AI进展的路线图将能在硅谷找到观众。
至于这一衡量方式会对政府官员和监管机构应对智能软件在隐私等方面的影响能有多大的帮助,现在还不清楚,华盛顿大学法律系教授 Ryan Calo表示:“我不知道它会有多么有用。”他最近提出了AI政策问题的详细路线图。他认为,决策者需要对底层技术进行深度的了解,而且需要强有力的价值观,而不是对细微的进步进行监控。
EFF的 Eckersley 认为,AI 追踪项目将随着时间的推移变得更加有用。例如,有关失业问题的辩论可能会通过关于软件程序如何快速推动某些工作人员的核心任务进行自动化的数据而被提及。Eckersley说,看这个领域的进展情况已经有助于说服他自己,让AI系统更加可信赖是多么的重要。他说:“我们收集的数据表明AI系统的安全性是一个相关甚至紧迫的研究领域。”
学术界和谷歌等公司的研究人员最近已经调查了如何欺骗人工智能软件,并防止它的错误行为。随着各家公司都在急切地用软件来控制诸如汽车等更为普遍的技术上,如何使其可靠和安全可衡量的进步可能是最重要的。
第9期R语言数据分析&机器学习初级实战课程正在火热报名中!扫码送课程详细介绍!

未来的制造业要的不是石油,它最大的能源是数据.